
A Vector adatbázisok: Az adatbázisok új korszaka
Az adatbázisok olyan rendszerek, amelyek lehetővé teszik az adatok tárolását, szervezését és keresését, az adatbázis típusa pedig az adatok tárolásának és szervezésének módját határozza meg. A hagyományos adatbázisok általában táblázatokban tárolják az adatokat, amelyekben minden sor egy adatot tartalmaz, és minden oszlop egy tulajdonságot vagy jellemzőt. A hagyományos adatbázisok képesek hatékonyan kezelni a szöveges adatokat, azonban képtelenek hatékonyan kezelni a bonyolultabb objektumokat, mint például a képek vagy a hangfájlok.
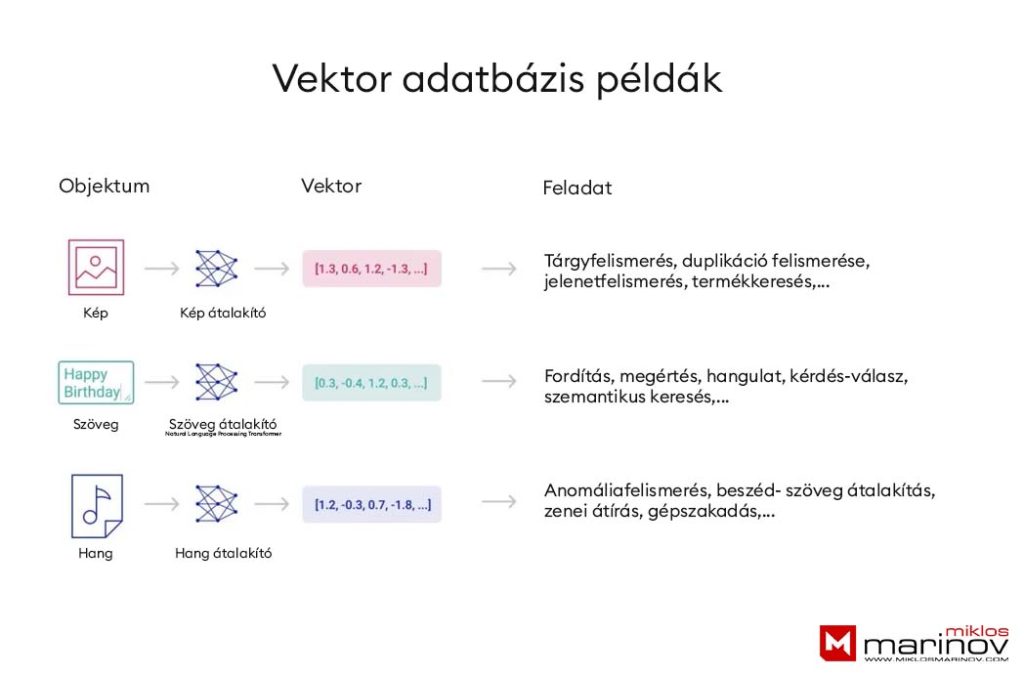
A Vector adatbázisok azonban megoldást nyújtanak a bonyolultabb objektumok tárolására és keresésére. Az embeding, vagyis az beágyazás lehetővé teszi az objektumok ábrázolását vektorokká, amelyeket könnyen összehasonlíthatunk és hasonlóságot lehet számolni közöttük. Ez nagyon hasznos az AI-alapú alkalmazások számára, amelyeknek szükségük van az objektumok közötti hasonlóságokra.
Az ilyen típusú adatbázisok nem csak az embedingen alapulnak, hanem egyéb technológiák is beépíthetők, amelyek még hatékonyabbá teszik az adatok kezelését és a keresést. Vannak például időben változó adatbázisok, amelyek az adatok változását is képesek kezelni. Vagy léteznek gráf adatbázisok, amelyek képesek a bonyolult kapcsolatokat ábrázolni az adatok között. Ezeknek az adatbázisoknak további előnye is van a hagyományos adatbázisokhoz képest. Az egyik ilyen előny, hogy lehetőség van az adatok gyors tárolására és keresésére a vektorokban. Ez azért fontos, mert az AI alkalmazások gyors reakcióidőt igényelnek, amikor nagy mennyiségű adatot kell feldolgozni.
Egy népszerű Vector adatbázis a Cassandra, amely nagy teljesítményű, elosztott adatbázis, amely lehetővé teszi az adatok tárolását és kezelését a skálázhatóság és a rendelkezésre állás szempontjából is. A MongoDB egy másik népszerű adatbázis, amely támogatja az ágyazási technológiát és a dokumentumalapú adatmodellezést. A Weaviate és a Milvus nyílt forrású Vector adatbázisok, amelyek Go nyelven íródtak, míg a Pinecone nagyon népszerű, de nem nyílt forrású. Az ilyen típusú adatbázisok kiegészítik a hagyományos adatbázisokat a vektoros funkciókhoz való támogatással.
A legizgalmasabb rész az, hogy képesek bővíteni a nyelvi modelleket hosszú távú memóriával. Ez azt jelenti, hogy ha van egy általános célú modellünk, mint például az OpenAI GPT-4 vagy a Google Lambda, akkor saját vektor adatbázisunkkal képesek vagyunk felhasználni saját adatbázisunkból a releváns dokumentumokat, és így az AI meg tudja emlékezni a korábbi keresések eredményeire, hogy finomhangolja a válaszait.
Az AI alkalmazások fejlesztése során a Vector adatbázisok az utóbbi időkben nagyon népszerűvé váltak. Egyre több cég használja őket, hogy hatékonyabb és pontosabb szolgáltatásokat nyújthassanak ügyfeleiknek. Például a Pinterest használ Vector adatbázist a képek javaslatok személyre szabásához, a Airbnb pedig a szálláshelyek ajánlása során.
Ha további információra van szükséged a Vector adatbázisokkal kapcsolatban, akkor érdemes lehet megnézni a Wikipédia oldalát erről a témáról: https://en.wikipedia.org/wiki/Vector_database. Itt több információt találhatsz azokról a cégnevekről, amelyek használnak Vector adatbázist, és további részleteket a működésükről és előnyeikről.